SynthDrive
Telematics data: synthetically generated, actuarial-grade
SynthDrive on Snowflake Marketplace →
SynthDrive generates policy-level synthetic telematics portfolios—driver variables, vehicle variables, usage and driving-behavior signals, claim counts, and claim amounts—without requiring access to proprietary insurer data.
Usage-Based Insurance (UBI)
The diagram illustrates how a usage-based insurance system works from data collection through to pricing and claims outcomes.
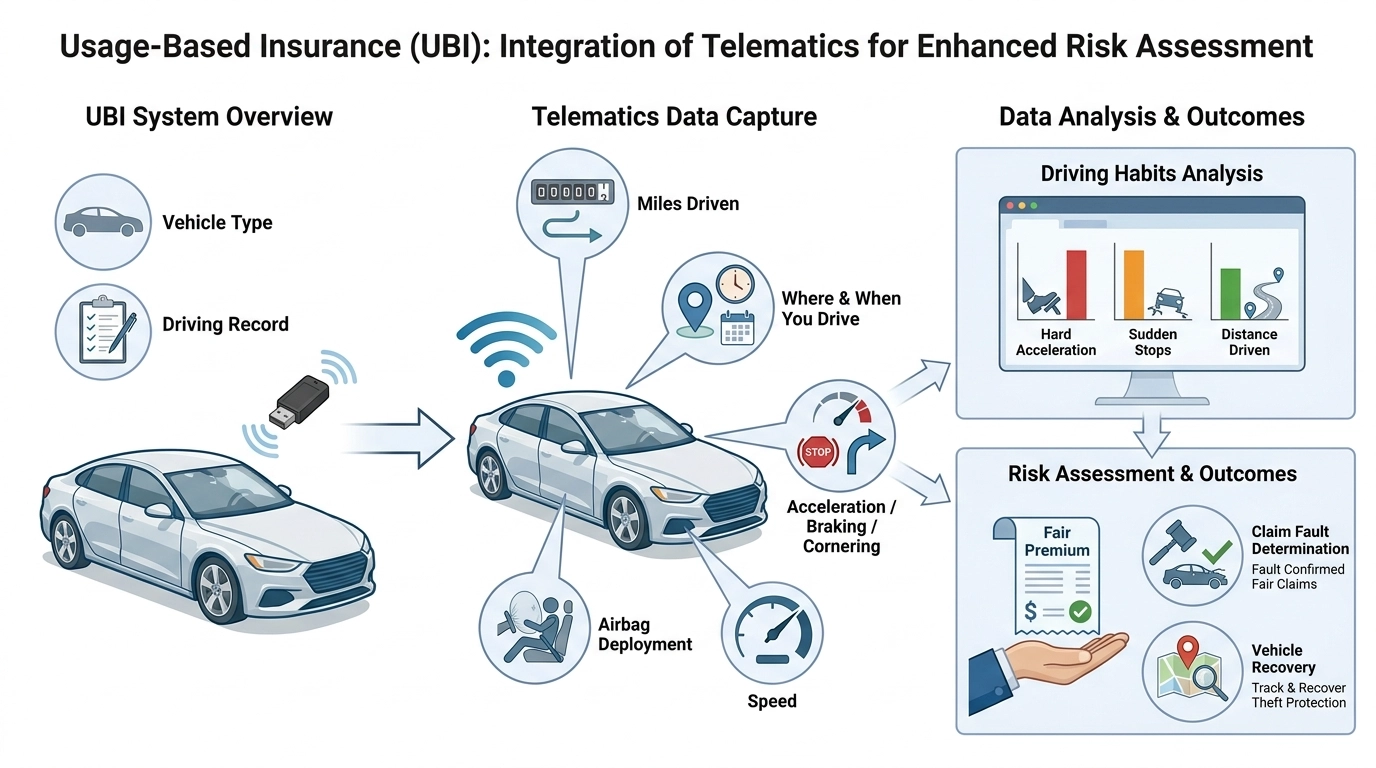
A telematics device captures how, when, and how far a vehicle is driven — along with hard acceleration, harsh braking, and cornering events. That behavioral data replaces demographic proxies in the risk assessment, producing a premium calibrated to actual driving rather than assumed risk, and supporting downstream functions like fault determination and vehicle recovery.
How SynthDrive Works
You specify a portfolio size and a random seed; SynthDrive returns a reproducible dataset with the actuarial structure needed for pricing, fraud, and UBI model development.
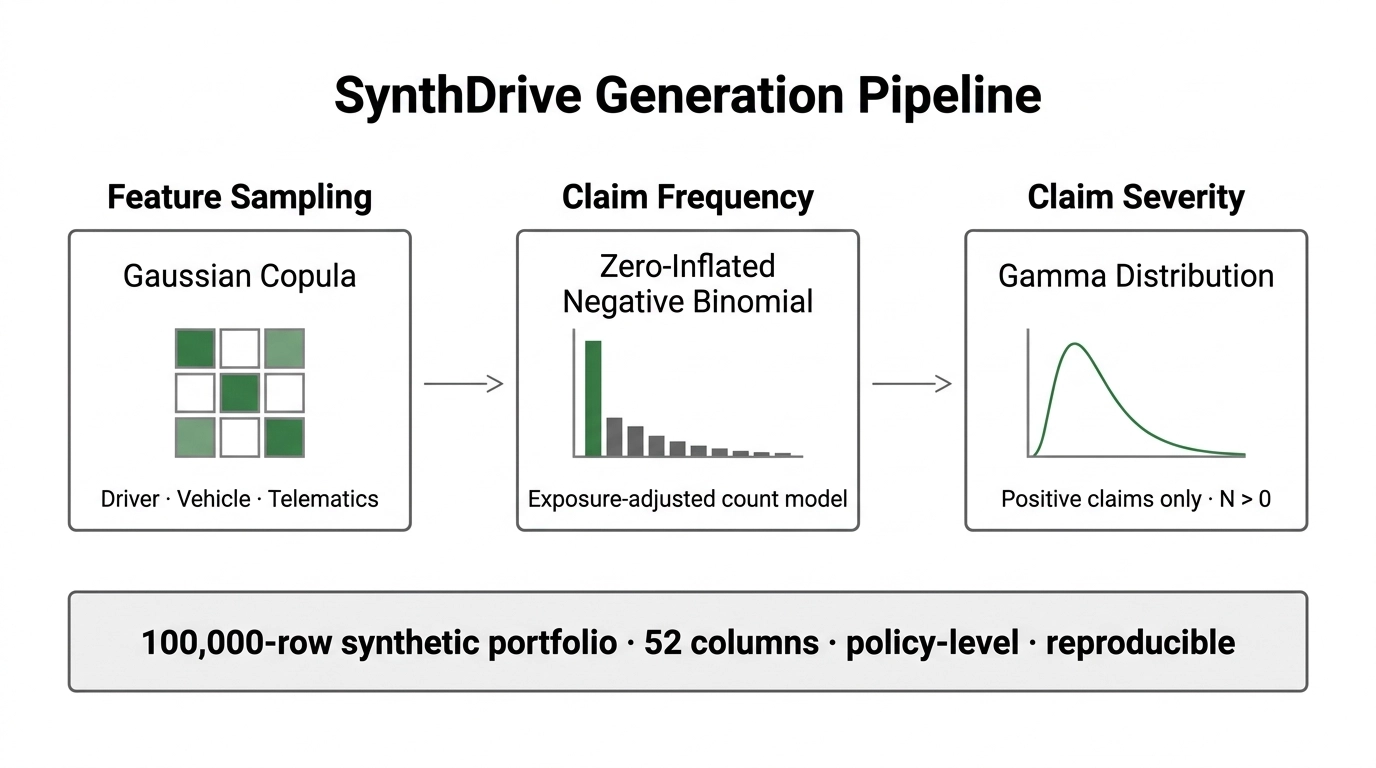
SynthDrive has a three-stage generation pipeline. From left to right, a Gaussian copula samples correlated driver, vehicle, and telematics features jointly; a zero-inflated negative binomial model assigns claim counts with an exposure offset, reflected in the characteristic zero-spike frequency distribution shown at center; and a Gamma model draws claim amounts for policies with at least one claim, shown as a right-skewed severity density at right. The three stages feed into a single output portfolio of 100,000 policy-level rows across 52 columns.
The methodology behind SynthDrive is described in (Homayounfar, 2026).
What Makes It Unique
- Constraint-aware by design. Compositional driving variables are enforced to sum correctly, exposure bounds are hard constraints, and claim amounts are zero whenever claim counts are zero. The dataset cannot be silently invalid.
- Frequency-severity decomposition built in. Claim counts follow a zero-inflated negative binomial model with an exposure offset. Severity is drawn from a Gamma model, risk-adjusted per policy. The pipeline matches the standard actuarial GLM framework, not a black-box regressor.
- Validated against a public benchmark. GLM coefficients, marginal distributions, and frequency relativities are compared against the So–Boucher–Valdez (2021) public synthetic telematics dataset. The validation report documents what the generator reproduces, what is approximate, and what is not tested.
Use Cases
- Build and benchmark UBI pricing models without requesting proprietary insurer data.
- Test frequency and severity GLMs, GBMs, or neural claim models on a controlled synthetic portfolio before applying them to real data.
- Evaluate synthetic-data algorithms against a structured actuarial baseline with known ground truth.
How It Works
SynthDrive generates each synthetic policy in three steps: a Gaussian copula produces correlated driver, vehicle, and telematics variables; a zero-inflated negative binomial model assigns claim counts scaled to exposure; and a Gamma model draws claim amounts for policies that claim. No neural networks, no GPU.
Parameters are calibrated from public synthetic telematics datasets. (So et al., 2021; Duval et al., 2022)
Open-Source Access
The SynthDrive package is available on GitHub under an open-source license. Source code, documentation, and the formal algebraic specification are included in the repository.
Further Details
For research collaborations or licensing inquiries, contact us.
References
2026
2022
- T&FHow much telematics information do insurers need for claim classification?North American Actuarial Journal, Jun 2022
2021
- MDPI